Part 7:栈和函数
在这一部分我们来看一下进程中叫做栈的内存区域。本章涵盖了栈的用途和相关操作。此外我们将介绍 ARM 中函数的实现、类型和差异。
栈
一般而言,栈就是进程中的一段内存。这段内存是在进程创建时分配的。我们使用栈来保存一些临时数据,如函数中的局部变量,函数之间转换的环境变量等。使用PUSH和POP指令与栈进行交互。在Part 4:内存指令:加载与存储中我们讲到PUSH和POP是一些其他内存操作指令的别名,这里为简单起见我们使用PUSH和POP指令。
在看实例之前,我们先要明白栈有多种实现方式。首先,当我们说栈增长了,意思是一个数据(32位)被放入了栈中。栈可以向上增长(当栈是按照降序方式实现)或者向下增长(当栈是按照升序方式实现)。下一条信息将被放置的实际位置是由栈指针定义的。准确的说是保存在寄存器SP中的地址指定的。地址可以是栈中的当前(最后入栈)项或者下一个可用的内存位置。如果SP指向的是栈中的最后一个项(完整栈实现方式),那么是先增加(向上增加栈)或减小(向下增长栈)SP再放入数据;如果SP指向的是栈内下一个有效的空位置,那么是数据先入栈后再增加SP(向上增加栈)或减少SP(向下增长栈)。
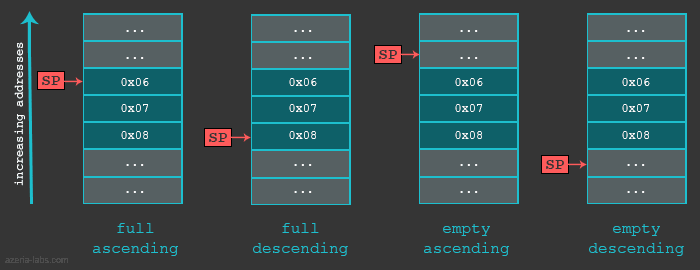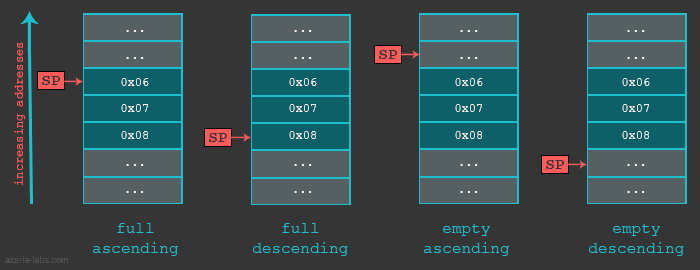
总结了栈的不同实现,我们可以用以下表格列出了不同情况下使用不同的多数据存储或多数据加载指令。

我们的例子中使用了完整降序栈(Full descending)。下面是一个简单例子,看一下这种栈是如何处理栈指针的。
/* azeria@labs:~$ as stack.s -o stack.o && gcc stack.o -o stack && gdb stack */
.global main
main:
mov r0, #2 /* 设置R0的初始值*/
push {r0} /* 将R0的值保存到栈*/
mov r0, #3 /* 覆盖R0的值 */
pop {r0} /* 恢复R0的初始值 */
bx lr /* 结束程序 */在一开始,栈指针指向地址0xbefff6f8 (你的环境中可能不同)代表栈中的最后一项值。这时我们看一下这个地址处的值(同样,你的环境中可能不同):
gef> x/1x $sp
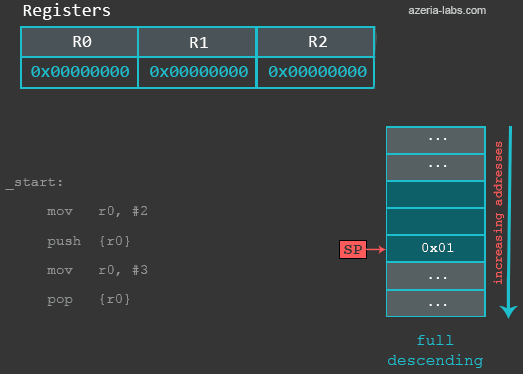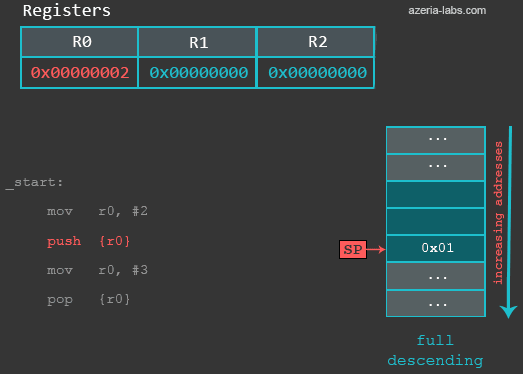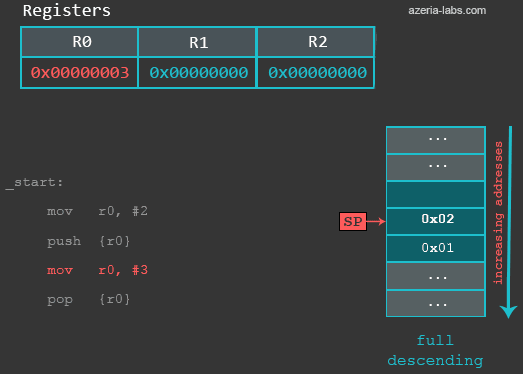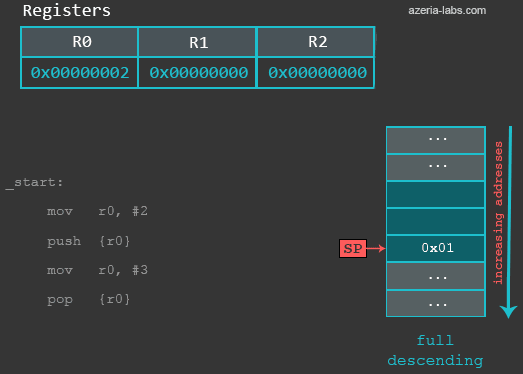
0xbefff6f8: 0xb6fc7000当执行完第一条MOV指令后,栈内数据没有变化。当执行PUSH指令时,将发生以下事情:首先SP的值减4(4 bytes = 32 bits);然后R0中的值保存到SP指定的地址处。现在再看一下SP中指定的地址处的值:
gef> x/x $sp
0xbefff6f4: 0x00000002例子中的指令mov r0, #3用来模拟R0中的数据被覆盖的情形。然后使用POP再将之前的数据恢复。所以,当执行POP指令时,实际发生了以下事情:首先从当前SP指向的内存地址(0xbefff6f4)处读取一个32位的数据(前面PUSH时保存的2),然后SP寄存器的值减4(变成0xbefff6f8 ),最后将从栈中读取的数值2保存到R0。
gef> info registers r0
r0 0x2 2(注意,下面的gif展示的栈的低地址在上面,高地址在下面。不是前面展示不同堆栈实现时的图片的那种方式,这样是为了让栈看起来跟GDB中展示一样):
我们看一下函数如何利用Stack来保存本地变量、保留寄存器状态。为了让一切变得井然有序,函数使用栈帧(专门用于函数中使用的局部内存区域)。栈帧是在函数开始调用时创建的(下一节将详细介绍)。栈帧指针(FP)被置为栈帧的底部,然后分配栈帧的缓冲区。栈帧中通常(从底部)保存了返回地址(前面的LR寄存器值)、栈帧指针、其他一些需要保存的寄存器、函数参数(如果超过4个参数)、局部变量等等。虽然栈帧的实际内容可能有所不同,但基本就这些。最后栈帧在函数结束时被销毁。
下面是栈中栈帧的示意图:

为了直观点,再看一段代码:
/* azeria@labs:~$ gcc func.c -o func && gdb func */
int main()
{
int res = 0;
int a = 1;
int b = 2;
res = max(a, b);
return res;
}
int max(int a,int b)
{
do_nothing();
if(a<b)
{
return b;
}
else
{
return a;
}
}
int do_nothing()
{
return 0;
}下面的GDB截图中我们可以看一下栈帧的样子:

从上图中我们可以看到,当前我们即将离开函数max(反汇编代码底部的箭头)时,这时,FP(R11寄存器)指向栈帧最底部的0xbefff254。看栈中的绿色地址保存了返回地址0x00010418(前面的LR寄存器)。再往上4字节的地址处(0xbefff250)保存值0xbefff26c,这是前一个栈帧指针(FP)。地址0xbefff24c和0xbefff248处的0x1和0x2是函数max运行时的局部变量。所以刚才分析的这个栈帧只包含了LR,FP和两个局部变量。
函数
要理解ARM中的函数,首先要熟悉函数体的结构:开始、执行体和收尾。
开始时需要保存程序前面的状态(LR和R11分别入栈)然后为函数的局部变量设置堆栈。虽然开始部分的实现可能因编译器而异,但通常是用PUSH/ADD/SUB指令来完成的。大体看起来是下面这样:
push {r11, lr} /* 将lr和r11入栈 */
add r11, sp, #0 /* 设置栈帧的底部位置 */
sub sp, sp, #16 /* 栈指针减去16为局部变量分配缓存区 */函数体部分就是你程序的实际逻辑区,包含了你代码逻辑的各种指令:
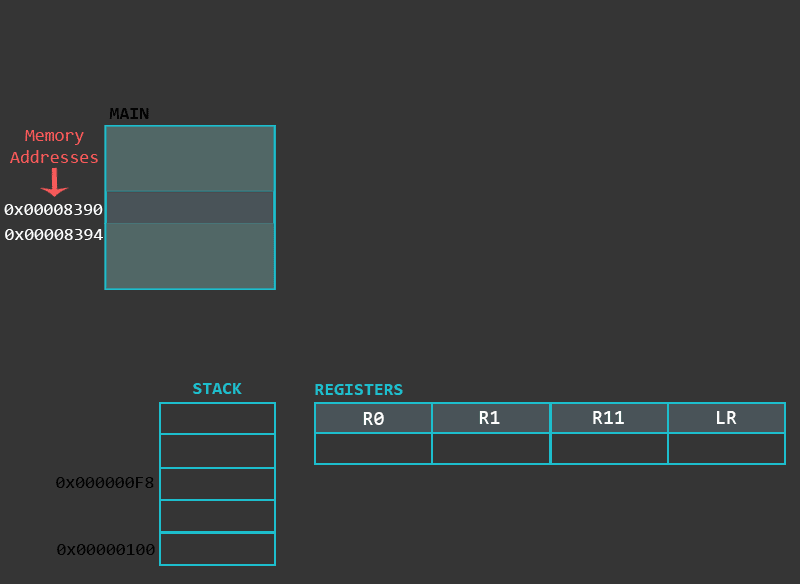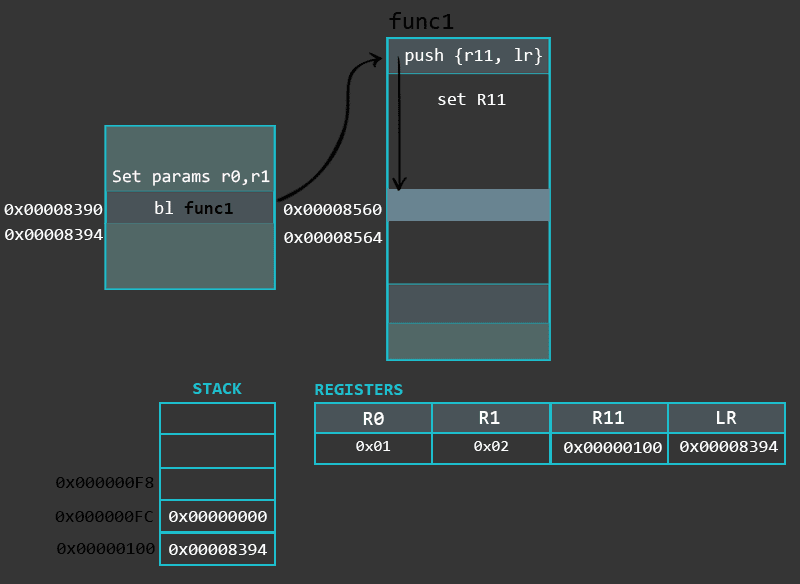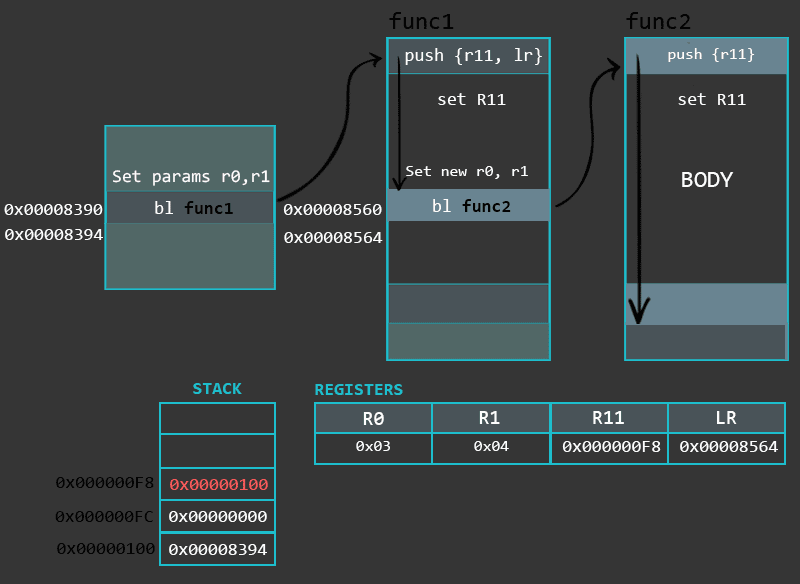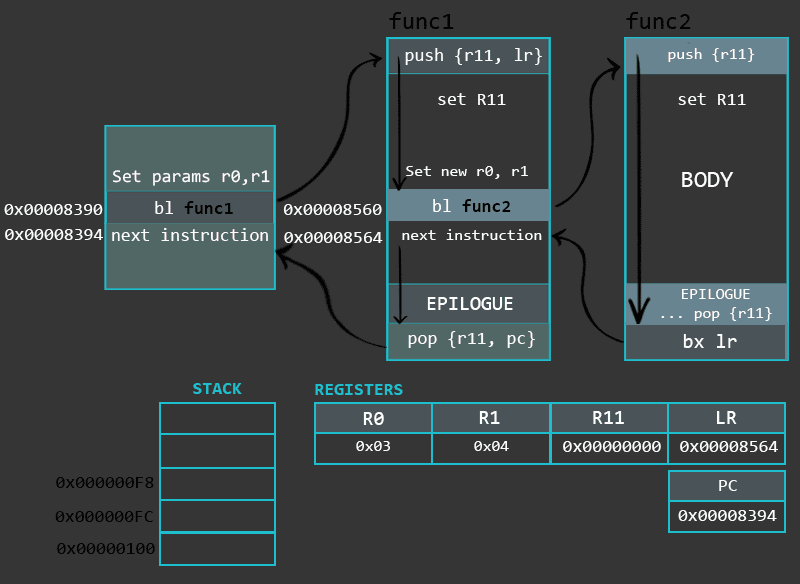
mov r0, #1 /* 设置局部变量(a=1). 同时也为函数max的第一个参数 */
mov r1, #2 /* 设置局部变量(b=2). 同时也为函数max的第二个参数 */
bl max /* 调用函数max */上面的代码展示了为函数设置局部变量并跳转到另一个函数的过程。同时还展示了通过寄存器为另一个函数(max)传递参数的过程。在某些情况下,当要传递的参数超过4个时,我们需要另外使用栈来存储剩余的参数。还要说明一下,函数通过寄存器R0返回结果。所以不论max函数结果是什么,最后都要在函数结束返回后从R0中取返回值。在某些情况下,结果可能是 64 位的长度(超过 32 位寄存器的大小),这时候就需要结合R0和R1来存储返回值。
函数的最后部分用于将程序的状态还原到它初始的状态(函数调用前),这样就可以从函数被调用的地方继续执行。所以我们需要重新调整栈指针(SP)。这是通过加减帧指针寄存器(R11)来实现的。重新调整栈指针后,将之前(函数开始处)保存的寄存器值从堆栈弹出到相应的寄存器来还原这些寄存器值。根据函数类型,一般POP指令是函数最后结束的指令。但是,在还原寄存器值后,我们需要使用 BX 指令来离开函数。示例如下:
sub sp, r11, #0 /* 重新调整栈指针 */
pop {r11, pc} /* 恢复栈帧指针, 通过加载之前保存的LR到PC,程序跳转到之前LR保存位置。函数的栈帧被销毁 */所以我们现在知道:
- 函数在开始时设置相应的环境。
- 函数体中执行相关逻辑,然后通过R0保存返回值。
- 函数收尾时恢复所有的状态,以便程序可以在函数调用前的位置继续执行。
另一个重要的知识点时函数类型:叶子函数和非叶子函数。叶子函数在函数内不会调用/跳转到另一个函数。非叶子函数则会在自己的函数逻辑中调用另一个函数。这两种函数的实现方式类似。不过,也有一些不同。我们用下面的代码分析一下:
/* azeria@labs:~$ as func.s -o func.o && gcc func.o -o func && gdb func */
.global main
main:
push {r11, lr} /* 开始,栈帧指针和LR分别入栈 */
add r11, sp, #0 /* 设置栈帧的底部(译注:其实是将sp的值给R11,栈指针指向初始的栈帧指针位置(栈帧底部)) */
sub sp, sp, #16 /* 在栈上分配一些内存作为接下来局部变量要用的缓存区(译注:栈指针减16,相当于将栈帧指针往下移动了16字节)) */
mov r0, #1 /* 设置局部变量 (a=1). 同时也为函数max准备参数a */
mov r1, #2 /* 设置局部变量 (b=2). 同时也为函数max准备参数b */
bl max /* 跳转到函数max */
sub sp, r11, #0 /* 重新调整栈指针 */
pop {r11, pc} /* 恢复栈帧指针, 通过加载之前保存的LR到PC,程序跳转到之前LR保存位置 */
max:
push {r11} /* 开始,栈帧指针入栈 */
add r11, sp, #0 /* 设置栈帧底部 */
sub sp, sp, #12 /* 栈指针减12,分配栈内存 */
cmp r0, r1 /* 比较R0和R1(a和b) */
movlt r0, r1 /* 如果R0<R1, 将R1存储到R0 */
add sp, r11, #0 /* 收尾,调整栈指针 */
pop {r11} /* 恢复栈帧指针 */
bx lr /* 通过寄存器LR跳转到main函数 */上面的例子包含两个函数:main函数是一个非叶子函数,max函数是叶子函数。之前说了非叶子函数有跳转到其他函数的逻辑(bl , max),而max中没有(最后一条是跳转到LR指定的地址,不是函数分支)这类代码,所以是叶子函数。
另一个不同点是函数的开始与收尾的实现有差异。来看一段代码,这是叶子函数与非叶子函数在开始部分的差异:
/* 非叶子函数 */
push {r11, lr} /* 分别保存栈帧指针和LR */
add r11, sp, #0 /* 设置栈帧底部 */
sub sp, sp, #16 /* 在栈上分配缓存区*/
/* 叶子函数 */
push {r11} /* 保存栈帧指针 */
add r11, sp, #0 /* 设置栈帧底部 */
sub sp, sp, #12 /* 在栈上分配缓存区 */不同之处是非叶子函数保存了更多的寄存器。原因也很自然,因为非叶子函数中执行时LR会被修改,因此要先保存LR以便最后恢复。当然如果有必要也可以在函数开始时保存更多的寄存器。
下面这段代码可以看到,叶函数与非叶函数在收尾时的差异主要是在于,叶子函数在结尾直接通过LR中的值跳转回去,而非叶子函数需要先通过POP恢复LR寄存器,再进行分支跳转。
/* A prologue of a non-leaf function */
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, #0 /* Setting up the bottom of the stack frame */
sub sp, sp, #16 /* End of the prologue. Allocating some buffer on the stack */
/* A prologue of a leaf function */
push {r11} /* Start of the prologue. Saving Frame Pointer onto the stack */
add r11, sp, #0 /* Setting up the bottom of the stack frame */
sub sp, sp, #12 /* End of the prologue. Allocating some buffer on the stack */最后,我们要再次强调一下在函数中BL和BX指令的使用。在我们的示例中,通过使用BL指令跳转到叶子函数中。在汇编代码中我们使用了标签,在编译过程中,标签被转换为相对应的内存地址。在跳转到对应位置之前,BL会将下一条指令的地址存储到LR寄存器中这样我们就能在函数max结束的时候返回了。
BX指令在被用在我们离开一个叶函数时,使用LR作为寄存器参数。刚刚说了LR存放着函数调用返回后下一条指令的地址。由于叶函数不会在执行时修改LR寄存器,所以就可以通过LR寄存器跳转返回到main函数了。同样可以使用BX指令帮助我们切换ARM模式和Thumb模式。可以通过LR寄存器的最低比特位来完成,0代表ARM模式,1代表Thumb模式。
换一种方式看一下函数及其内部,下面的动画说明了非叶子函数和叶子函数的内部工作过程。



![ARM语法 Part 6[条件状态和分支]](/medias/featureimages/18.jpg)